本文中的代码均采用GPL v3协议发布
前言
由于现在电脑CPU的单核性能提升已经遇到瓶颈,最近AMD与Intel的处理器也通过堆核来大幅提高性能,主流处理器早已达到了达到了8核16线程。因此,合理利用好多核性能对程序运行速度的提升非常重要。最近我打算简单体验一下Python的multiprocessing库中的多进程功能~~~
在摸鱼过程中,顺便学习了一下两个打包工具——nuitka和pyinstaller的使用(当然,我尝试打包了Windows版本,由于Linux的大多数发行版均已经预装Python,并没有什么打包的必要)
多进程踩坑经历
应用场景选择
在尝试multiprocessing库之前首先应当选择一个合适的应用场景,要求计算处理的对象可以分成若干块并行计算。我选择的是数值积分,因为数值积分是将积分区间分割成很多小段,求出每个小段的面积之后再相加。求面积的过程是相互独立的,不依赖之前的结果,计算任务也基本上是重复算小段面积和累加,所以可以将大的积分区间分成若干个小区间,分别求出每个区间的值,最后再相加即可。这种计算任务写成多进程比较方便
代码
单进程的代码
其实选择数值积分器这个应用还有一个原因,那就是单进程积分器的代码我以前写过🤪🤪🤪🤪🤪🤪
为了提高精度,我这里没有采用矩形法(常函数)或梯形法(一次函数)进行拟合,而是使用了辛普森法(二次函数)拟合
#!/usr/bin/env python3
from timeit import default_timer as time
from math import *
# 按照习惯名称对部分函数定义别名
def ln(x):
return log(x)
def lg(x):
return log(x, 10)
def arcsin(x):
return asin(x)
def arccos(x):
return acos(x)
def arctan(x):
return atan(x)
def arcsinh(x):
return asinh(x)
def arccosh(x):
return acosh(x)
def arctanh(x):
return atanh(x)
print('注意:三角函数请先化成正弦、余弦、正切及相应的反三角函数(现已支持双曲三角函数及对应的反三角函数)\n 请务必使用半角符号;圆周率请用"pi"表示;自然对数的底数请用"e"表示\n 请用"*""/"表示乘除,"**"表示乘方,"abs"表示绝对值,"ln"或"log"表示自然对数,"lg"表示常用对数,"log(m, n)"表示m对于底数n的对数\n请输入被积函数(用x表示自变量):') # 预备信息
fx = input()
print('请输入积分的下限:')
start = eval(input()) # 使用eval函数,支持输入表达式
print('请输入积分的上限:')
end = eval(input())
print('请输入分割数(由于浮点数值运算具有不精确性,分割数过大反而可能增大误差)')
block = int(input())
calcstart = time() # 输入结束,计算开始,计时
length = (end - start) / block
halflength = length / 2
out = 0
x = start
temp2 = eval(fx) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
for i in range(1, block + 1): # 积分运算,辛普森法
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
print('\n完成!计算耗时:{}s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
改为多进程
我这里选择了的是multiprocessing中的Pool进行多进程运算,Pool能为我的程序提供很多便利:
- 方便批量建立进程
- 内置了
Pool(n).map()(仅支持一个参数)和Pool(n).starmap()(支持多个参数)函数,是map()函数的进程池版本,可以多进程地对可迭代对象进行目标函数操作,并返回map对象 - 返回对象处理方便,只需要套一层
sum()函数就能得到最终结果
定义积分函数
由于Pool.starmap()需要输入函数,所以需要定义每一个进程的积分函数:
# 用于积分的函数
def integration(blockstart, blockend):
out = 0
x = start + blockstart*length
temp2 = eval(fx) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
for i in range(blockstart + 1, blockend + 1):
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
return out
进程数与区间分段
当然,还需要将积分区间分成若干段,段数应当与进程数匹配。为了充分利用CPU各个虚拟核心算力,可以先调用from os import cpu_count再通过n = cpu_count()获取CPU的线程数以设置进程数,也可以设定其他合理的进程数(如物理核心数等)
from os import cpu_count
n = cpu_count() # 默认为设备的逻辑核心数
tile = int(block / n)
# 进行分段,以便分进程计算
tilestart = 0
obj = [0]
for i in range(n):
tilestart += tile
obj.append(tilestart)
初版整体代码
from timeit import default_timer as time
from os import cpu_count
n = cpu_count() # 默认为设备的逻辑核心数
from multiprocessing import Pool
from math import *
def ln(x):
return log(x)
def lg(x):
return log(x, 10)
def arcsin(x):
return asin(x)
def arccos(x):
return acos(x)
def arctan(x):
return atan(x)
def arcsinh(x):
return asinh(x)
def arccosh(x):
return acosh(x)
def arctanh(x):
return atanh(x)
print('注意:三角函数请先化成正弦、余弦、正切及相应的反三角函数(现已支持双曲三角函数及对应的反三角函数)\n 请务必使用半角符号;圆周率请用"pi"表示;自然对数的底数请用"e"表示\n 请用"*""/"表示乘除,"**"表示乘方,"abs"表示绝对值,"ln"或"log"表示自然对数,"lg"表示常用对数,"log(m, n)"表示m对于底数n的对数\n请输入被积函数(用x表示自变量):')
fx = input()
print('请输入积分的下限:')
start = eval(input())
print('请输入积分的上限:')
end = eval(input())
print('请输入分割数(建议为CPU逻辑核心数的正整数倍;由于浮点数值运算具有不精确性,分割数过大反而可能增大误差):')
block = int(input())
calcstart = time()
length = (end - start) / block
halflength = length / 2
tile = int(block / n)
# 用于积分的函数
def integration(blockstart):
out = 0
x = start + blockstart*length
temp2 = eval(fx) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
if blockstart == tilestart:
blockend = block
else:
blockend = blockstart + tile
for i in range(blockstart + 1, blockend + 1):
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
return out
# 进行分段,以便分线程计算
tilestart = 0
obj = [0]
for i in range(n):
tilestart += tile
obj.append(tilestart)
# 分线程计算
with Pool(n) as pool:
out = sum(pool.map(integration, obj))
# 显示输出
print('\n完成!计算耗时:{} s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
踩坑:初版代码运行结果
以上代码在我的Linux平台上运行毫无问题:
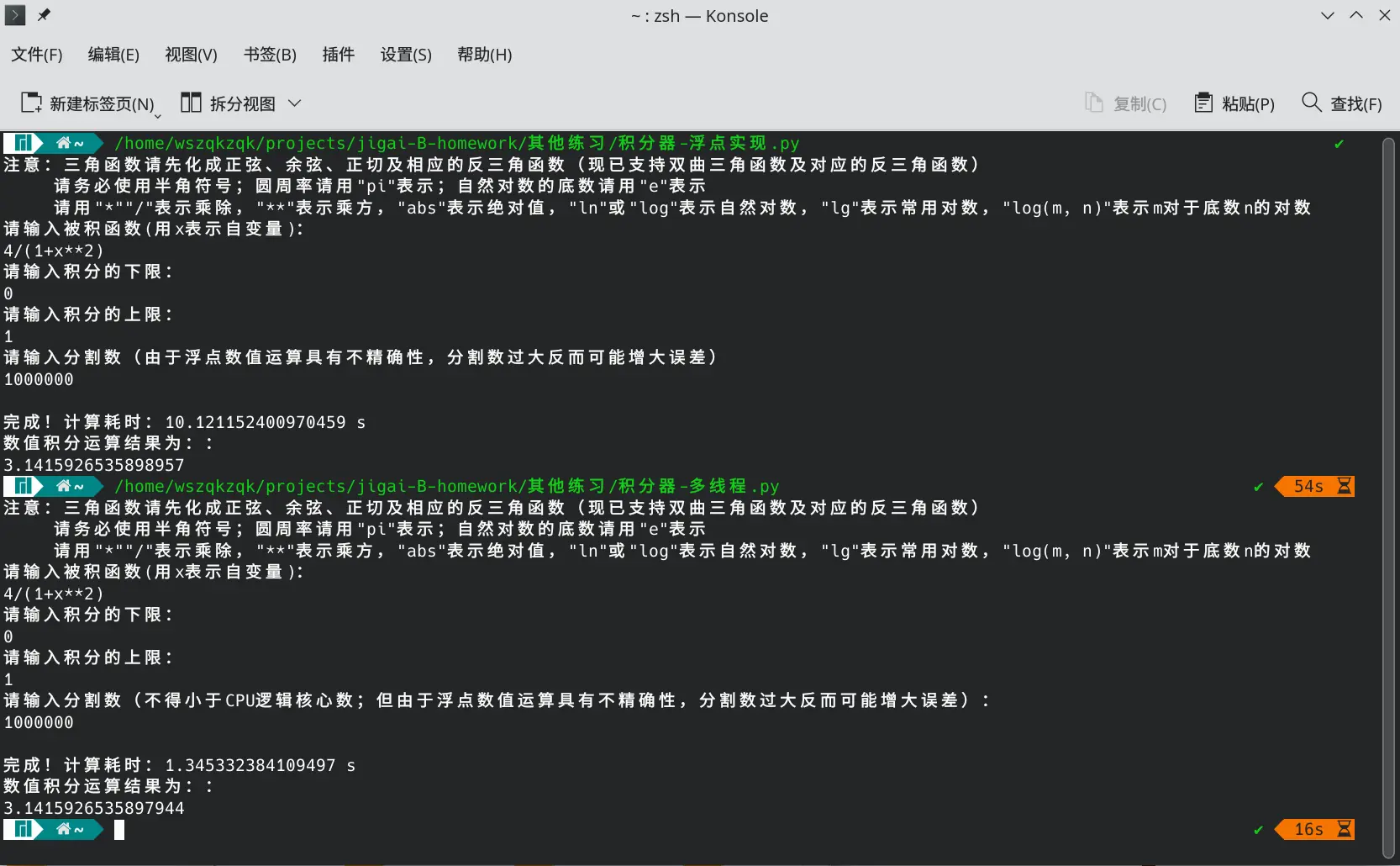 |
|---|
| Linux下单进程与多进程程序效率对比:在100,0000次分割的高计算量下,多进程程序效率是单进程程序的7.5倍 1 |
但是在Windows下会出现以下情况:
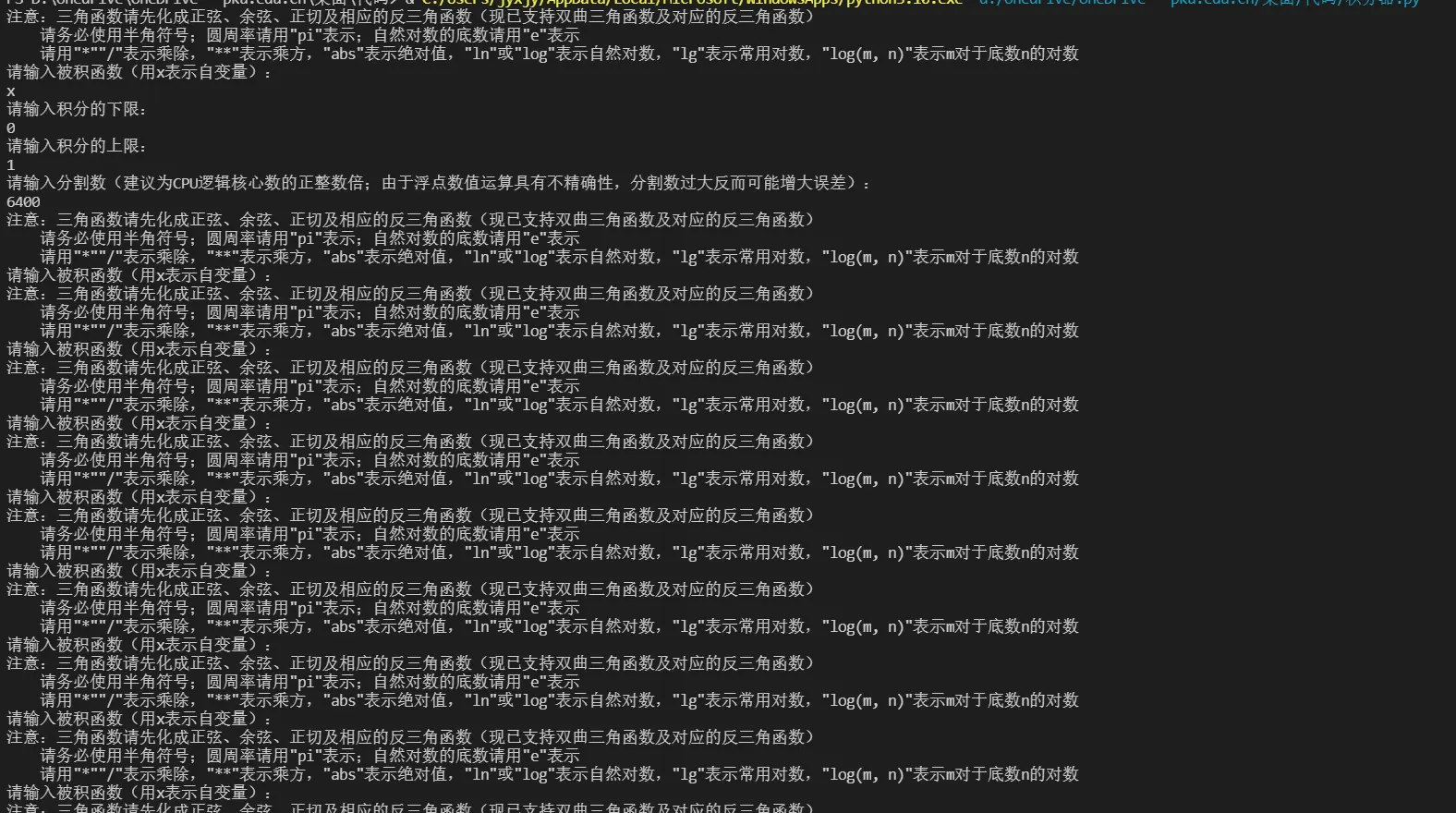 |
|---|
| Windows平台下各个子进程从头执行程序,并非只执行目标函数 |
经过查证,出现该问题的原因是Windows和Linux(POSIX)的子进程实现方式不同,Windows下是spawn而POSIX中是fork,前者相比于后者对代码有更严格的要求,对于spawn方式,需要将不在子进程中执行的代码用if __name__ == '__main__':保护起来,使其只能在主进程中执行
同时spawn的子进程没有保留主进程中的全局变量,因此所有变量都需要通过参数传递给进程函数
问题修复后的情况
代码
修复问题后,以下代码在Windows下得以正常运行:
#!/usr/bin/env python3
from math import *
def ln(x):
return log(x)
def lg(x):
return log(x, 10)
def arcsin(x):
return asin(x)
def arccos(x):
return acos(x)
def arctan(x):
return atan(x)
def arcsinh(x):
return asinh(x)
def arccosh(x):
return acosh(x)
def arctanh(x):
return atanh(x)
if __name__ == '__main__':
from platform import system
if system() == 'Windows':
print('检测到您在Windows平台下,Windows下多进程初始化耗时较久,当计算量过小时无法发挥性能优势')
from timeit import default_timer as time
from os import cpu_count
n = cpu_count() # 默认为设备的逻辑核心数
from multiprocessing import Pool
print(' 多进程积分器 <一个简单的多进程数值积分工具>\n Copyright (C) 2021-2022 星外之神 <wszqkzqk@qq.com>\n\n注意:三角函数请先化成正弦、余弦、正切及相应的反三角函数(现已支持双曲三角函数及对应的反三角函数)\n 请务必使用半角符号;圆周率请用"pi"表示;自然对数的底数请用"e"表示\n 请用"*""/"表示乘除,"**"表示乘方,"abs"表示绝对值,"ln"或"log"表示自然对数,"lg"表示常用对数,"log(m, n)"表示m对于底数n的对数\n请输入被积函数(用x表示自变量):')
fx = input()
print('请输入积分的下限:')
start = eval(input())
print('请输入积分的上限:')
end = eval(input())
print('请输入分割数(建议为CPU逻辑核心数的正整数倍;由于浮点数值运算具有不精确性,分割数过大反而可能增大误差):')
block = int(input())
calcstart = time()
length = (end - start) / block
halflength = length / 2
tile = int(block / n)
# 用于积分的函数
def integration(blockstart, blockend, start, length, halflength, fx):
out = 0
x = start + blockstart*length
temp2 = eval(fx) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
for i in range(blockstart + 1, blockend + 1):
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
return out
if __name__ == '__main__':
# 进行分段,以便分进程计算
tilestart = 0
obj = []
for i in range(n - 1):
tileend = tilestart + tile
obj.append((tilestart, tileend, start, length, halflength, fx))
tilestart = tileend
obj.append((tilestart, block, start, length, halflength, fx))
# 分进程计算
with Pool(n) as pool:
out = sum(pool.starmap(integration, obj))
# 显示输出
print('\n完成!计算耗时:{}s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
性能状况
经过多次运行与比较,我发现该程序在Linux下的运行效率明显高于Windows(积分分割数为100,0000时Windows耗时2.8s,而Linux仅耗时1.3s),且Windows平台下空载(输入常函数,积分区间为0,分割数为1)耗时竟高达0.6s(Linux空载只需要0.03s)1
我认为造成Windows下程序运行较慢的原因有两个:
- Windows下进程资源消耗较Linux(POSIX)大,建立进程耗时长(经过验证,空载的时间消耗主要来自建立进程池这一步)
- 因为Windows下的
spawn是直接新建一个进程,而POSIX的fork是利用写时复制技术在原有进程基础上建立新的进程,spawn的资源占用比fork大得多
- 因为Windows下的
- Windows下官方版Python是用MSVC编译的,性能较GCC编译的差(虚拟机(8线程)Windows系统中用MinGW编译的Python运行该程序的速度甚至比实体机(16线程)上的快)
Windows下exe的编译
为了优化该程序在Windows下的性能,我开始在Windows中寻找编译该程序为exe文件的方法,试图在编译过程中选择使用GCC与Clang代替MSVC,提高程序运行效率
现在仍然积极开发的编译方案主要有pyinstaller和nuitka
pyinstaller
使用pip install pyinstaller安装,通过pyinstaller -F file.py(-F表示输出为单个文件)将file.py编译成exe文件,默认输出到命令执行目录的dist文件夹中
pyinstaller编译的并非是机器码文件,它只是将代码编译为python字节码(.pyc文件),然后将其与解释器和所需要的库封装到一起,因此也不依赖C编译器。然而,我并没有搞清这个pyinstaller封装的是所在Python环境的解释器还是自身库所携带的Python解释器(懒~),所以其实并不一定有性能提升
但是,当我运行编译后的exe程序时,那个bug又出现了:
解决办法
查资料得知,编译为文件夹时可以在代码中加入from multiprocessing import freeze_support与freeze_support解决,但是,编译为单个文件时不支持多进程,使用此方法依然无效
- 此外,假如该程序没有输入这一步阻隔后续步骤,由于每次建立进程都会完整启动一遍程序,将会无限建立进程,导致内存泄漏,把程序变为“内存炸弹”
- 因此用pyinstaller编译python多进程程序风险很大,一不小心就做成了一个病毒般的东西
所以我只有放弃用pyinstaller编译多进程积分器的想法,但是我依然在Clang的Python环境下编译了一个单进程积分器(点此下载)
- 原理上pyinstaller是将
python.dll目标.pyc文件封装在一起,因此实际上pyinstaller并不能显著优化python程序的速度
nuitka
与pyinstaller不同,nuitka是先将.py文件编译为.c源代码,再将.c源代码编译为python解释器可以识别的二进制文件,因此,nuitka需要C编译器才能运行
- 然而,这里的二进制文件并非直接由机器执行,而仍然是调用python解释器进行解释,因此并不会拥有C语言的运行效率
- Nuitka的编译主要是把python的PyObject抽离到C中
- 由于Nuitka在编译过程中有所优化,因此Nuitka编译的程序相比编译前有一定的性能提升
- 根据我的简单测试,四则运算中整数、浮点运算均有越2~3倍的性能提升,其中浮点运算性能提升更加明显
踩坑:编译器支持
在Windows平台下,nuitka支持三个C编译器,分别是MSVC、MinGW、Clang,我本来准备调用Clang进行编译,但是编译的时候发现nuitka只支持MSVC中的Clang而不支持MSYS2中的Clang,因此不能编译
- 2022.05.31更新:与nuitka作者取得联系后,作者告知可以用
--mingw64 --clang来使用MSYS2(MingW-w64)中的Clang
踩坑:Python安装来源
我改用MinGW编译器之后,同步切换到了MinGW编译的Python环境,但是在此环境中运行时,nuitka可能无法兼容MinGW提供的Python,报出了找不到python39.lib的错误,不知道怎么解决
- 2022.02.17更新:现在从Msys2官方源pacman安装的Nuitka已经可用了,但是不能在
bash、zsh、fish这样的Msys2终端中执行,否则会因为错误调用/usr/lib中的库而编译失败(应当调用的是/mingw64/bin中的库,不知道为什么在Msys2终端中会出现这个错误,可能是Msys2终端指定了默认值???) - 2022.05.31更新:可以取消
bash、zsh、fish启动的--login参数,或者直接在cmd、powershell、pwsh中启动bash、zsh、fish来避免这一问题
我又换到了MSStore里面的Python环境,然而nuitka依然不兼容
最后,我从Python官网下载Python才解决了这个问题
编译
nuitka除了依赖C编译器外,还需要其他几个库的支持,好在nuitka在运行过程中可以自动解决依赖问题,因此也并不算麻烦;我编译多进程积分器的命令如下:
nuitka --mingw64 --standalone --onefile --show-progress --show-memory --enable-plugin=multiprocessing --windows-icon-from-ico=target.ico --output-dir=out targetfile.py
MSYS2的各个shell可能无法识别Windows的.bat文件,需要将命令改为:
python -m nuitka --mingw64 --standalone --onefile --show-progress --show-memory --enable-plugin=multiprocessing --windows-icon-from-ico=target.ico --output-dir=out targetfile.py
如果是使用MSYS2中的python和Nuitka(即安装的是${MINGW_PACKAGE_PREFIX}-python-nuitka),则可执行:
nuitka3 --mingw64 --standalone --onefile --show-progress --show-memory --enable-plugin=multiprocessing --windows-icon-from-ico=target.ico --output-dir=out targetfile.py
- 2022.04.06更新:
- 现在的Nuitka版本(0.7.7)已经默认启用
multiprocessing模块,无需在命令中体现 - 执行
nuitka --mingw64 --standalone --onefile --show-progress --show-memory --windows-icon-from-ico=target.ico --output-dir=out targetfile.py即可
- 现在的Nuitka版本(0.7.7)已经默认启用
其中,--mingw64是指定C编译器(默认为MSVC),--standalone是打包依赖,--onefile是要求程序打包为一个文件,--show-progress是显示编译过程,--show-memory是显示内存占用情况,--enable-plugin=multiprocessing是启用多进程支持,--output-dir=out是指定输出目录为当前目录下的out文件夹,最后的targetfile.py则是待编译的文件
注意:文件路径不支持中文
- 2022.01.23更新:编译是否成功似乎与路径是否含中文无关,但是输出路径最好不要为绝对路径,否则很容易出问题(可以就直接设置为
out)
这可能是Windows的路径名规则与Unix不符所致 - 2022.05.31更新:现在好像没有这一限制了
编译程序体积压缩
在没有压缩的情况下,nuitka编译的程序占用体积高达24 MB(pyinstaller编译的程序只有不到7 MB),因此,有必要对程序进行压缩
其实nuitka默认启用了压缩,但压缩依赖第三方库,假如没有安装zstandard便无法压缩,因此,建议运行pip install zstandard后再进行编译,zstd压缩处理速度很快,而且压缩的exe文件大小仅8 MB左右
- 2022.05.17更新:Nuitka 0.7以上版本打包文件大小进一步减小,仅5.5 MB左右
此外,nuitka似乎仅支持Python中的zstandard,并不能调用MSYS2中的zstd
- 这个压缩是生成一个压缩了的但是可以直接运行的exe文件,并不是生成一个zst文件,否则就没有意义了(
- 2022.04.03更新:对于
MSYS2中的python,可以直接用pacman安装对应的mingw-w64-$(ARCHNAME)-python-zstandard软件包
踩坑:细节
由于编译成了exe,使用者可能在资源管理器中直接双击打开而不专门在Windows终端中运行,因此,在这种情况下当程序运行结束时,计算结果会一闪而过,不方便使用者查看
在代码末尾加一个input('\n请按回车键退出')就能解决这个问题
代码
#!/usr/bin/env python3
from math import *
def ln(x):
return log(x)
def lg(x):
return log(x, 10)
def arcsin(x):
return asin(x)
def arccos(x):
return acos(x)
def arctan(x):
return atan(x)
def arcsinh(x):
return asinh(x)
def arccosh(x):
return acosh(x)
def arctanh(x):
return atanh(x)
if __name__ == '__main__':
from timeit import default_timer as time
from os import cpu_count
n = cpu_count() # 默认为设备的逻辑核心数
from multiprocessing import Pool
print(' 多进程积分器 <一个简单的多进程数值积分工具>\n Copyright (C) 2021-2022 星外之神 <wszqkzqk@qq.com>\n\n注意:三角函数请先化成正弦、余弦、正切及相应的反三角函数(现已支持双曲三角函数及对应的反三角函数)\n 请务必使用半角符号;圆周率请用"pi"表示;自然对数的底数请用"e"表示\n 请用"*""/"表示乘除,"**"表示乘方,"abs"表示绝对值,"ln"或"log"表示自然对数,"lg"表示常用对数,"log(m, n)"表示m对于底数n的对数\n请输入被积函数(用x表示自变量):')
fx = input()
print('请输入积分的下限:')
start = eval(input())
print('请输入积分的上限:')
end = eval(input())
print('请输入分割数(建议为CPU逻辑核心数的正整数倍;由于浮点数值运算具有不精确性,分割数过大反而可能增大误差):')
block = int(input())
calcstart = time()
length = (end - start) / block
halflength = length / 2
tile = int(block / n)
# 用于积分的函数
def integration(blockstart, blockend, start, length, halflength, fx):
out = 0
x = start + blockstart*length
temp2 = eval(fx) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
for i in range(blockstart + 1, blockend + 1):
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
return out
if __name__ == '__main__':
# 进行分段,以便分进程计算
tilestart = 0
obj = []
for i in range(n - 1):
tileend = tilestart + tile
obj.append((tilestart, tileend, start, length, halflength, fx))
tilestart = tileend
obj.append((tilestart, block, start, length, halflength, fx))
# 分进程计算
with Pool(n) as pool:
out = sum(pool.starmap(integration, obj))
# 显示输出
print('\n完成!计算耗时:{}s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
input('\n请按回车键退出')
性能
nuitka下调用MinGW编译的多进程积分器(点此下载)性能相比于MSVC编译的Python中运行的程序有一定的提高,接近在MinGW编译的Python中运行的水平,但是仍然与Linux下的性能表现有较大差距
编译的多进程积分器相比于官方版Python直接执行,空载启动时间由约0.6s下降到约0.3s,100,0000次分割运算时间由约2.8s下降到约2s 1
- 2022.01.21更新:这个积分器在Windows平台的运行速度受编译器影响似乎不是很大,让程序程序运行缓慢的真正原因可能是使用来自Microsoft Store中的Python;Python官网上的Python也是由MSVC编译而成,但是性能与MinGW编译的Python并没有明显差距(从Python官网上下载的Python空载启动时间约
0.35s,100,0000次分割运算时间约2s)。 - 2022.02.15更新:奇怪的是,wine运行Nuitka所打包的程序耗时空载耗时比Windows还短(仅需要
0.3s),100,0000次分割运算时间仍约2s,与Windows下的表现接近 - 2022.05.14更新:目前推测性能优化不明显的原因是该积分器最大的时间消耗在
eval一步字符串到表达式的转化,而这步操作对于编译器而言很难优化,所以耗时其实都差不多
关于代码的优化(2022.5.16更新)
之前示出的所有代码均使用eval()函数反复解析同一个字符串,这一步操作重复,且工作量巨大,因此可以予以优化。
为了避免对同一个字符串进行重复的编解码操作而造成性能浪费,Python内置了compile()函数,可以将字符串作为代码对象返回,并准备好执行。用compile()的结果替代原始字符串就能起到优化性能的作用。
此外,多进程程序调用的starmap()函数不支持传递用compile()函数编译后的代码对象,所以对字符串的编译应当放到各个进程中进行
开启优化后,程序的运算速度得到了大幅提升,单进程积分器对4/(1+x**2)在[0, 1]上进行分割100,0000次的数值积分耗时由10 ~ 11s大幅缩短到0.6 ~ 0.7s
代码
优化后的代码如下
单进程
#!/usr/bin/env python
# 积分器 <一个简单的数值积分工具>
# Copyright (C) 2021-2022 星外之神 <wszqkzqk@qq.com>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <https://www.gnu.org/licenses/>.
from timeit import default_timer as time
from math import *
def ln(x):
return log(x)
def lg(x):
return log(x, 10)
def arcsin(x):
return asin(x)
def arccos(x):
return acos(x)
def arctan(x):
return atan(x)
def arcsinh(x):
return asinh(x)
def arccosh(x):
return acosh(x)
def arctanh(x):
return atanh(x)
print(''' 积分器 <一个简单的数值积分工具>
Copyright (C) 2021-2022 星外之神 <wszqkzqk@qq.com>
注意:三角函数请先化成正弦、余弦、正切及相应的反三角函数(现已支持双曲三角函数及对应的反三角函数)
请务必使用半角符号;圆周率请用"pi"表示;自然对数的底数请用"e"表示
请用"*""/"表示乘除,"**"表示乘方,"abs"表示绝对值,"ln"或"log"表示自然对数,"lg"表示常用对数,"log(m, n)"表示m对于底数n的对数
请输入被积函数(用x表示自变量):''')
fx = compile(input(), '', 'eval')
print('请输入积分的下限:')
start = eval(input())
print('请输入积分的上限:')
end = eval(input())
print('请输入分割数(由于浮点数值运算具有不精确性,分割数过大反而可能增大误差)')
block = int(input())
calcstart = time()
length = (end - start) / block
halflength = length / 2
out = 0
x = start
temp2 = eval(fx) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
for i in range(1, block + 1):
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
print('\n完成!计算耗时:{}s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
input('\n请按回车键退出...')
多进程
#!/usr/bin/env python3
from math import *
def ln(x):
return log(x)
def lg(x):
return log(x, 10)
def arcsin(x):
return asin(x)
def arccos(x):
return acos(x)
def arctan(x):
return atan(x)
def arcsinh(x):
return asinh(x)
def arccosh(x):
return acosh(x)
def arctanh(x):
return atanh(x)
if __name__ == '__main__':
from timeit import default_timer as time
from os import cpu_count
n = cpu_count() # 默认为设备的逻辑核心数
from multiprocessing import Pool
print(' 多进程积分器 <一个简单的多进程数值积分工具>\n Copyright (C) 2021-2022 星外之神 <wszqkzqk@qq.com>\n\n注意:三角函数请先化成正弦、余弦、正切及相应的反三角函数(现已支持双曲三角函数及对应的反三角函数)\n 请务必使用半角符号;圆周率请用"pi"表示;自然对数的底数请用"e"表示\n 请用"*""/"表示乘除,"**"表示乘方,"abs"表示绝对值,"ln"或"log"表示自然对数,"lg"表示常用对数,"log(m, n)"表示m对于底数n的对数\n请输入被积函数(用x表示自变量):')
fx = input()
print('请输入积分的下限:')
start = eval(input())
print('请输入积分的上限:')
end = eval(input())
print('请输入分割数(建议为CPU逻辑核心数的正整数倍;由于浮点数值运算具有不精确性,分割数过大反而可能增大误差):')
block = int(input())
calcstart = time()
length = (end - start) / block
halflength = length / 2
tile = int(block / n)
# 用于积分的函数
def integration(blockstart, blockend, start, length, halflength, func):
out = 0
x = start + blockstart*length
fx = compile(func, '', 'eval')
temp2 = eval(fx) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
for i in range(blockstart + 1, blockend + 1):
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
return out
if __name__ == '__main__':
# 进行分段,以便分进程计算
tilestart = 0
obj = []
for i in range(n - 1):
tileend = tilestart + tile
obj.append((tilestart, tileend, start, length, halflength, fx))
tilestart = tileend
obj.append((tilestart, block, start, length, halflength, fx))
# 分进程计算
with Pool(n) as pool:
out = sum(pool.starmap(integration, obj))
# 显示输出
print('\n完成!计算耗时:{}s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
input('\n请按回车键退出')
自动判断
为了权衡开进程池的开销和多进程带来的性能提升,找到最优计算方案,这里默认在Windows平台下当分割数不大于100,0000时采用单进程计算,其余情况均采用多进程计算
此外,这个版本还增加了异常捕捉,在输入非法时不会闪退,而是会提示重新输入,更加方便
要使用的话推荐这个版本,当然这个程序是设计用来玩的()
Windows编译文件下载地址:点击这里下载(封装python 3.10环境,MSVC编译)
from math import *
from timeit import default_timer as time
from os import cpu_count
from os import name as systemName
from multiprocessing import Pool
n = cpu_count() # 默认为设备的逻辑核心数
def ln(x):
return log(x)
def lg(x):
return log(x, 10)
def arcsin(x):
return asin(x)
def arccos(x):
return acos(x)
def arctan(x):
return atan(x)
def arcsinh(x):
return asinh(x)
def arccosh(x):
return acosh(x)
def arctanh(x):
return atanh(x)
def integration(blockstart, blockend, start, length, halflength, func):
out = 0
x = start + blockstart*length
fx = compile(func, '', 'eval')
temp2 = eval(fx)
for i in range(blockstart + 1, blockend + 1):
temp0 = temp2
x += halflength
temp1 = eval(fx)
x = start + i*length
temp2 = eval(fx)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
return out
if __name__ == '__main__':
print(''' 积分器 <一个简单的数值积分工具(支持自动切换多进程)>
Copyright (C) 2021-2022 星外之神 <wszqkzqk@qq.com>
注意:三角函数请先化成正弦、余弦、正切及相应的反三角函数(现已支持双曲三角函数及对应的反三角函数)
请务必使用半角符号;圆周率请用"pi"表示;自然对数的底数请用"e"表示
请用"*""/"表示乘除,"**"表示乘方,"abs"表示绝对值,"ln"或"log"表示自然对数,"lg"表示常用对数,"log(m, n)"表示m对于底数n的对数
Windows下多进程初始化耗时较久,默认在分割数不小于100,0000时才启用多进程计算,其他平台则在任意分割数下均默认启用多进程计算
请输入被积函数(用x表示自变量):''')
fx = input()
while True:
try:
x = start = eval(input('请输入积分的下限:\n'))
break
except Exception:
print("错误!请检查后重新输入!")
while True:
try:
end = eval(input('请输入积分的上限:\n'))
break
except Exception:
print("错误!请检查后重新输入!")
while True:
try:
block = int(input('请输入分割数(建议为CPU逻辑核心数的正整数倍;由于浮点数值运算具有不精确性,分割数过大反而可能增大误差):\n'))
break
except Exception:
print("错误!请检查后重新输入!")
while True:
try:
func = compile(fx, '', 'eval')
temp2 = eval(func) # 初始化x与temp2,以便后续让temp0调用上一次的temp2的值,可以减小运算量
break
except Exception:
print("被积函数输入错误!请检查后重新输入!")
fx = input("请输入被积函数(用x表示自变量):\n")
calcstart = time()
length = (end - start) / block
halflength = length / 2
tile = int(block / n)
# 分割数较大时多进程计算
if (block >= 1000000) or (systemName != 'nt'):
# 进行分段,以便分进程计算
tilestart = 0
obj = []
for i in range(n - 1):
tileend = tilestart + tile
obj.append((tilestart, tileend, start, length, halflength, fx))
tilestart = tileend
obj.append((tilestart, block, start, length, halflength, fx))
with Pool(n) as pool:
out = sum(pool.starmap(integration, obj))
print('\n完成!计算耗时:{}s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
input('\n请按回车键退出...')
else:
out = 0
for i in range(1, block + 1):
temp0 = temp2
x += halflength
temp1 = eval(func)
x = start + i*length
temp2 = eval(func)
temp = (temp0 + 4*temp1 + temp2) / 6
out += temp*length
print('\n完成!计算耗时:{}s'.format(time() - calcstart))
print('数值积分运算结果为:')
print(out)
input('\n请按回车键退出...')
赞赏本文
| 支付宝 | 微信支付 |
|---|---|
 |
 |